弊社で大規模なアダルトサイトの運用を行う上でのAWS利用構成を紹介させて頂きます。
利用料金を抑えたいというビジネス的な観点と、サービスを止めない為の障害回避を念頭に構成を紹介します。
関連:AWSのt2.microで月間100万PVに耐えるアダルトサイトを制作した話
この記事は技術者向けの内容になっています。
システム開発の発注をお考えの方は、こちらアダルトホームページ制作のご案内をご覧下さい。
サービスを止めない為のAWS利用構成
サービスを止めない事は弊社では2つの思想によって設計をしております。
- 障害を防ぐ為の堅牢な設計とする
- 障害が起きた時に瞬時に復旧、あるいは回避する
前者はイメージしやすいと思いますが、弊社では後者のフェイルオーバーも非常に大事であると考えています。
システム障害が起きない様にスペックを十分に確保する等は当然の事ですが、
万が一障害が発生した場合に即座に代替機が立ち上がる等の手段によって、実質的に
サービスが停止しない様に設計する事が可能です。
障害発生時に自動的に復旧させる手段
AWSにおけるフェイルオーバーの代表的な実装手段は2つ存在しています。
- Elastic Load Balancingによるヘルスチェック
- Amazon Route53 のDNSによるヘルスチェック
前者については「障害を起こさない」という設計思想も兼ねていますが、EC2インスタンス自体に
障害が発生した際に自動的にホッとスタンバイ状態のインスタンスへ処理を移譲させます。
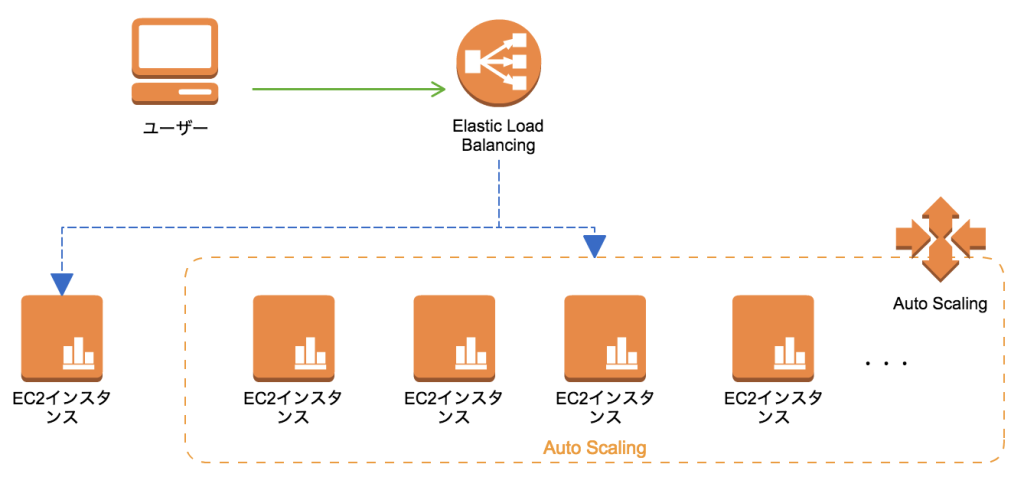
この障害回避はEC2インスタンスへのアクセス増が理由である一過性の障害理由に対しては
Auto Scaling と組み合わせる事で、非常に有効な対応策です。
逆にAmazon RDS等の連携サービスの不具合、アプリケーション自体の不具合による障害理由に対しては無力です。
Amazon Route53でDNSフェイルオーバー
Amazon Route53 のヘルスチェック機能を使う事で、障害が確認できた場合には
DNSフェイルオーバーによるDNS応答値の即座な変更機能を呼び出します。
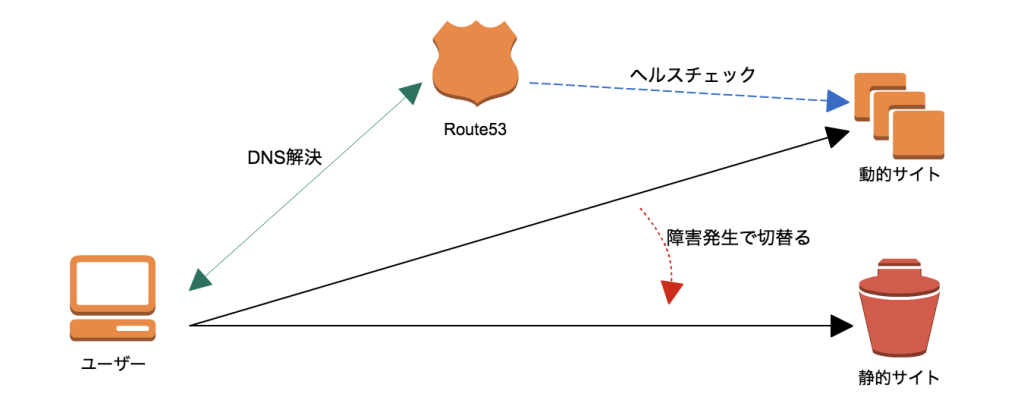
つまり、障害が起きたEC2インスタンス(或いはELB)のネットワークへ名前解決していた値を、
別のEC2インスタンス(或いはELB)のネットワークへ名前解決を変更させます。
この方法であれば、極端な話AWS以外の環境へも書き換えが有効で有ります。
別のEC2インスタンスではソーリーページを用意させるか、弊社の場合では
本来主たるEC2インスタンスによって生成されるべきページ内容をキャッシュさせ、静的に表示させる事をしております。
日本最大手の風俗情報ポータルサイトが既に風俗店にとって営業インフラと成りつつありますが、
サービスの一時停止により、風俗店の営業に大きな支障を来たした事は業界内では誰でも知っている事です。
そういった障害発生時にも、例えば店舗の電話番号が載ったソーリーページが1枚表示出来るだけでも
アクセスが出来ないという事態よりも、被害は最小限に出来ます。
堅牢なデータベースをAWSで実現する
Amazon RDS登場以降はEC2でデータベースサーバーを設計せずにRDSを使った設計が当たり前になっているかと思います。
RDSによって堅牢な環境を構築する上で、必須となっている事が マルチAZ です。
Amazonの仮想コンピューティング環境はアベイラビリティーゾーンと呼ばれる物理的に異なる空間を複数用意する事で、
仮に一つのネットワークに障害が発生しても、その障害を別のネットワークに影響を及ぼさない為の概念となっています。
RDSのマルチAZは、2台のインスタンスを異なるアベイラビリティーゾーンに配置させ、
自動的にレプリケーションを行なってくれます。
仮に障害が発生してもマルチAZのフェイルオーバープロセスによって、自動的にサービスが復旧されます。
フェイルオーバー時間は通常 60 ~ 120 秒です。
アプリケーションで使用されているデータベースがMySQLであり、予算が許す場合にはAmazon Auroraを積極的に利用すべきです。
Amazon Auroraではストレージレベルでの障害すら、自動的に復元する手段を備えております。
Amazon Aurora – MySQL 互換のリレーショナルデータベース
利用料金を抑える為のAWS利用構成
どうしてもアダルトサイトは夜間にアクセスが劇的に集中します。
スマートフォンの普及により、アクセス解析を見れば殆どがスマートフォンからのアクセスである事は明らかな話ですが
その為かベッドの中で閲覧される方が多いのでしょうか、昼間に比べ最大で10倍の開きが有ります。
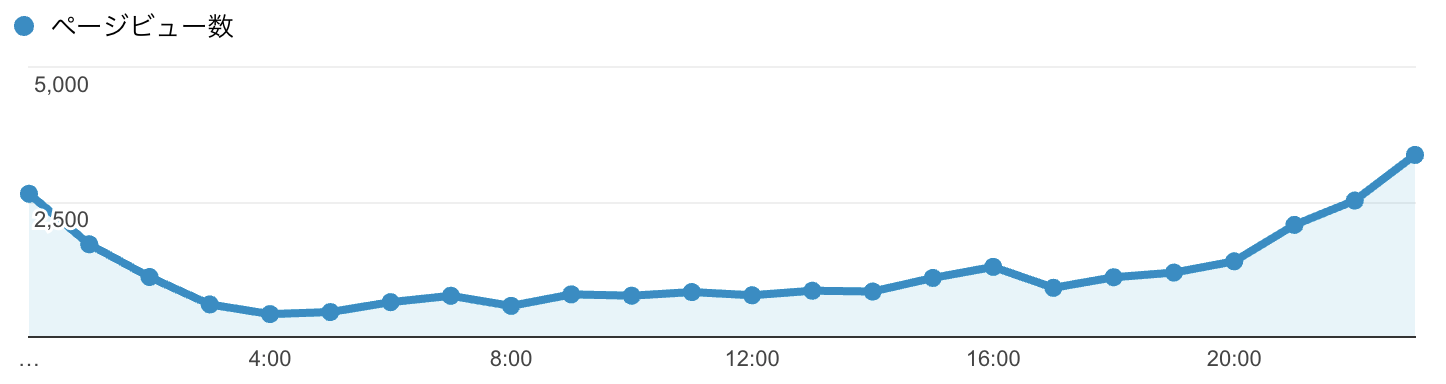
20時から午前2時までの6時間程度はアクセスが集中しますが、それ以外の時間帯は大したアクセス数は有りません。
今までのオンプレミス環境では20時から2時の最大限にアクセスが集中する時間に対応するサーバースペックを決めていましたが、
AWSの Auto Scalingを活用する事で昼間用の環境と夜間用の環境を分けた設計が可能です。
- AWS SDK によって、20時に自動的にELB配下のEC2インスタンスを起動
- 午前2時の時点でオンデマンド起動したEC2インスタンスを終了
このAWS環境設計によって、アクセスの集中する時間にのみインスタンス起動を行う事で
オンプレミス的な設計思想に比べて60%以上もサーバー維持費用を圧縮しながらも、安定した運用が実現出来ています。
EC2インスタンスの見積もり方法
AWSに限った話をせず、オンプレミス環境であってもサーバースペックを求める方法は単純です。
最大同時アクセス数にアプリケーションが消費するメモリ使用量を掛け合わせれば良いのです。
例えば、アプリケーションがPHPで書かれている場合には、プロセス内でのメモリ使用量を測定して下さい。
PHPでメモリ使用量を取得するプログラムコードは下記となります。
echo memory_get_peak_usage();
この関数の返り値によって、プロセス内で「5MB」のメモリ使用量が得られた場合
瞬間同時アクセス数を1000とした場合には、Apacheプロセスに最低でも5GBのメモリが確保できるサーバーであれば
要件を満たす事となります。
5GBのメモリーが確保すべきサービスであれば、OSによるメモリ使用量も勘案して
少なくとも8GBのメモリが搭載されたインスタンスを選ぶ事と成ります。
EC2インスタンス一覧表によれば、t2.largeかm4.large以上が必要要件となります。
Amazon EC2 インスタンス
画像や静的ファイルはCDNで高速配信
EC2はWebサーバーとして動作を完結できますので、EC2から画像ファイルなどを配信する事も可能ですが、
静的なファイルに関してはS3とCloudFrontを活用して処理負担を下げてしまう方が良い構成です。
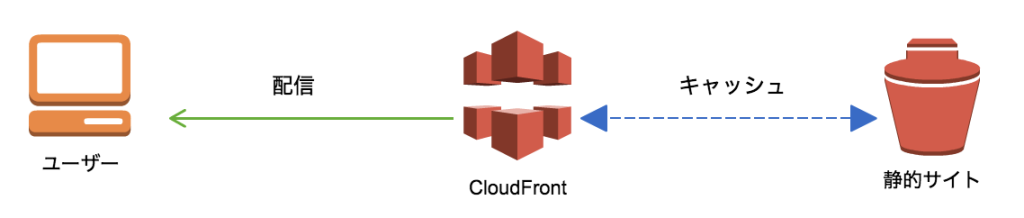
Amazon S3はストレージサービスである為、大規模なWebホスティングには向いていません。
HTTP(S)でのアクセスが提供されている為に、静的なWebホスティングに代用される例も実際に有りますが
そもそも高速な配信を想定された設計ではない為にパフォーマンス状の理由から正しい使い方では有りません。
Amazon S3はデータの置き場として飲み使い、実際にはCloud Front連携を行う事で、
S3のバケット上に存在するデータをCloud FrontというCDNサービスから効率良く高速に配信が可能です。
膨大な画像や動画データを転送する
大規模なアダルトサイトにとって、最もインフラ投資理由となるのは画像や動画の転送です。
AWSはデータ転送量の課金が高いと言われており、それを理由に別のクラウドサービスを利用する事も検討されるかもしれません。
特に大規模なアダルトサイトや、有料動画配信サービスを運用する場合を除いては、実質的に
AWS以外の転送量によって課金が発生しないクラウドサービスを使う方が、節約となるかもしれません。
弊社でもアプリケーションはAWSを利用していながらも、静的な画像類に限ってサクラのVPSを利用している例があります。
但し、転送量に影響されない料金体系が安いと言うのは、そもそも大したデータ転送量ではないと言う前提があります。
どう言う事かと言えば、月間1億PVあるようなアダルトサイトの場合、データ転送量は1ページ当たり1MBのデータ転送がある場合に
1秒間に約38MBのデータ転送量が必要となります。
この値はbit単位に直せば、300Mbpsの回線が要求されます。
このような大容量のデータ転送は、当然に通常の共有回線では捌く事が出来ず、利用を制限される事となります。
その為、大規模なアダルトサイトではAWSであっても、他のクラウドサービスと実質的に大差は無いと言えます。
画像を自動圧縮して転送量を削減
サムネイル等で使用する画像については、弊社ではAmazon Lambdaを使って自動的に圧縮するよう設計しています。
Amazon S3にアップロードされた場合に、Amazon SQSのイベントを受け取りAmazon Lambda Functionによって画像圧縮をしています。
表示されるサムネイルに応じたサイズ通りに画像が圧縮される様になっていれば、1ページ当たりの転送量を削減可能です。
この方法によってデータ転送が最適化されたかは、「Google Page Speed Insights」によって確認する事が出来ます。
モバイルフレンドリーテスト
因みに動画ファイルについても Amazon Elastic Transcoder を用いて同様に最適化を行えます。
実際に問題が発生した時の人的なフォロー
AWSで障害検知によって自動的に復旧する手段を確保する事が出来ますが、本当に自動復旧が成功したか否か
自分の目で確かめる事が必要になります。いち早く障害検知を伝える方法として弊社ではAmazon SNSとTwilioを活用しています。
電話をAPIにする Twilio
どうしてもEメールやSMSですと気づかないケースもある為、障害検知のイベントをAmazonSNSに渡し、予め
Twilioで用意した架電APIへリクエストを送信する様にしています。
この方法によって、Twilioから技術担当者へ架電される為、夜中だろうが嫌でも目覚める事になります。。。
問題が起きない事に越したことは無いですが、不測の事態は常に起きるものだと考え、設定をお勧めします。